
- SpreadJS 개요
- 시작하기
- JavaScript 프레임워크
- 모범 사례
- 기능
- SpreadJS 템플릿 디자이너
- SpreadJS 디자이너 컴포넌트
- 터치 지원
-
수식 참조
- 수식 개요
-
수식 종류
- 바코드 함수
- 호환성 함수
- 데이터베이스 함수
- 날짜/시간 함수
- 공학 함수
- 재무 함수
- 정보 함수
- 논리 함수
- 찾기/참조 영역 함수
- 수학/삼각 함수
-
통계 함수
- AVEDEV
- AVERAGE
- AVERAGEA
- AVERAGEIF
- AVERAGEIFS
- BETA.DIST
- BETA.INV
- BINOM.DIST
- BINOM.DIST.RANGE
- BINOM.INV
- CHISQ.DIST
- CHISQ.DIST.RT
- CHISQ.INV
- CHISQ.INV.RT
- CHISQ.TEST
- CONFIDENCE.NORM
- CONFIDENCE.T
- CORREL
- COUNT
- COUNTA
- COUNTBLANK
- COUNTIF
- COUNTIFS
- COVARIANCE.P
- COVARIANCE.S
- DEVSQ
- EXPON.DIST
- F.DIST
- F.DIST.RT
- F.INV
- F.INV.RT
- F.TEST
- FINV
- FISHER
- FISHERINV
- FORECAST
- FREQUENCY
- GAMMA
- GAMMA.DIST
- GAMMA.INV
- GAMMALN
- GAMMALN.PRECISE
- GAUSS
- GEOMEAN
- GROUPBY
- GROWTH
- HARMEAN
- HYPGEOM.DIST
- INTERCEPT
- KURT
- LARGE
- LINEST
- LOGEST
- LOGNORM.DIST
- LOGNORM.INV
- MAX
- MAXA
- MAXIFS
- MEDIAN
- MIN
- MINA
- MINIFS
- MODE.MULT
- MODE.SNGL
- NEGBINOM.DIST
- NORM.DIST
- NORM.S.DIST
- NORM.S.INV
- NORMINV
- PEARSON
- PERCENTOF
- PERCENTILE.EXC
- PERCENTILE.INC
- PERCENTRANK.EXC
- PERCENTRANK.INC
- PERMUT
- PERMUTATIONA
- PHI
- PIVOTBY
- POISSON.DIST
- PROB
- QUARTILE.EXC
- QUARTILE.INC
- RANK.AVG
- RANK.EQ
- RSQ
- SKEW
- SKEW.P
- SLOPE
- SMALL
- STANDARDIZE
- STDEV.P
- STDEV.S
- STDEVA
- STDEVPA
- STEYX
- T.DIST
- T.DIST.2T
- T.DIST.RT
- T.INV
- T.INV.2T
- T.TEST
- TREND
- TRIMMEAN
- VAR.P
- VAR.S
- VARA
- VARPA
- WEIBULL.DIST
- Z.TEST
- 스파크라인 함수
- 텍스트 함수
- 웹 함수
- RegEx 함수
- 기타 함수
- 가져오기 및 내보내기 참조
- 자주 사용하는 이벤트
- API 문서
- 릴리스 노트
COVARIANCE.P
이 함수는 모집단 공분산을 반환합니다. 모집단 공분산은 두 숫자 집합에서 각 데이터 쌍의 편차 곱의 평균입니다.
구문
COVARIANCE.P(array1, array2)
인수
이 함수의 두 데이터 배열은 다음 조건을 만족해야 합니다:
데이터는 숫자, 이름, 배열 또는 숫자형 참조를 포함해야 합니다. 일부 셀이 숫자 데이터를 포함하지 않는 경우 무시됩니다.
데이터 집합은 크기가 같아야 하며, 데이터 포인트 수가 동일해야 합니다.
데이터 집합이 비어 있으면 안 되며, 값의 표준편차가 0이어서는 안 됩니다.
참고
이 공분산 함수는 두 데이터 집합 간의 관계를 결정하는 데 사용됩니다. 예를 들어, 모집단에서 소득이 많을수록 교육 수준도 높은지 여부를 판단할 수 있습니다.
공분산은 다음과 같이 계산됩니다. 여기서 n과 y는 샘플 평균 AVERAGE(array1) 및 AVERAGE(array2)이며, n은 샘플 크기입니다.
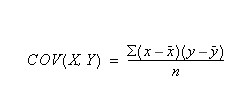
데이터 유형
두 인수 모두 숫자 데이터 배열을 허용하며, 숫자 데이터를 반환합니다.
예시
COVARIANCE.P(J2:J5,L2:L5)
COVARIANCE.P(R2C12:R15C12,R2C14:R15C14)
COVARIANCE.P({7,5,6},{7,4,4})는 결과로 1을 반환합니다.
COVARIANCE.P({5,10,15,20,25},{4,8,16,32,64})는 결과로 144를 반환합니다.