
- SpreadJS 개요
- 시작하기
- JavaScript 프레임워크
- 모범 사례
- 기능
- SpreadJS 템플릿 디자이너
- SpreadJS 디자이너 컴포넌트
- 터치 지원
-
수식 참조
- 수식 개요
-
수식 종류
- 바코드 함수
- 호환성 함수
- 데이터베이스 함수
- 날짜/시간 함수
- 공학 함수
- 재무 함수
- 정보 함수
- 논리 함수
- 찾기/참조 영역 함수
- 수학/삼각 함수
-
통계 함수
- AVEDEV
- AVERAGE
- AVERAGEA
- AVERAGEIF
- AVERAGEIFS
- BETA.DIST
- BETA.INV
- BINOM.DIST
- BINOM.DIST.RANGE
- BINOM.INV
- CHISQ.DIST
- CHISQ.DIST.RT
- CHISQ.INV
- CHISQ.INV.RT
- CHISQ.TEST
- CONFIDENCE.NORM
- CONFIDENCE.T
- CORREL
- COUNT
- COUNTA
- COUNTBLANK
- COUNTIF
- COUNTIFS
- COVARIANCE.P
- COVARIANCE.S
- DEVSQ
- EXPON.DIST
- F.DIST
- F.DIST.RT
- F.INV
- F.INV.RT
- F.TEST
- FINV
- FISHER
- FISHERINV
- FORECAST
- FREQUENCY
- GAMMA
- GAMMA.DIST
- GAMMA.INV
- GAMMALN
- GAMMALN.PRECISE
- GAUSS
- GEOMEAN
- GROUPBY
- GROWTH
- HARMEAN
- HYPGEOM.DIST
- INTERCEPT
- KURT
- LARGE
- LINEST
- LOGEST
- LOGNORM.DIST
- LOGNORM.INV
- MAX
- MAXA
- MAXIFS
- MEDIAN
- MIN
- MINA
- MINIFS
- MODE.MULT
- MODE.SNGL
- NEGBINOM.DIST
- NORM.DIST
- NORM.S.DIST
- NORM.S.INV
- NORMINV
- PEARSON
- PERCENTOF
- PERCENTILE.EXC
- PERCENTILE.INC
- PERCENTRANK.EXC
- PERCENTRANK.INC
- PERMUT
- PERMUTATIONA
- PHI
- PIVOTBY
- POISSON.DIST
- PROB
- QUARTILE.EXC
- QUARTILE.INC
- RANK.AVG
- RANK.EQ
- RSQ
- SKEW
- SKEW.P
- SLOPE
- SMALL
- STANDARDIZE
- STDEV.P
- STDEV.S
- STDEVA
- STDEVPA
- STEYX
- T.DIST
- T.DIST.2T
- T.DIST.RT
- T.INV
- T.INV.2T
- T.TEST
- TREND
- TRIMMEAN
- VAR.P
- VAR.S
- VARA
- VARPA
- WEIBULL.DIST
- Z.TEST
- 스파크라인 함수
- 텍스트 함수
- 웹 함수
- RegEx 함수
- 기타 함수
- 가져오기 및 내보내기 참조
- 자주 사용하는 이벤트
- API 문서
- 릴리스 노트
VAR.P
이 함수는 전체 모집단을 기준으로 분산을 반환하며 숫자 값만 사용합니다.
구문
VAR.P(value1, value2, ...)
VAR.P(array)
VAR.P(array1, array2, ...)
인수
각 인수는 배정밀도 부동소수점 값, 정수 값, 또는 이들의 배열(셀 범위)일 수 있습니다. 최대 255개의 인수를 포함할 수 있습니다. 값 목록 대신 단일 배열(셀 범위)을 사용할 수 있으며, 여러 배열(셀 범위)도 사용할 수 있습니다.
참고
분산은 데이터 집합이 얼마나 퍼져 있는지를 나타냅니다.
인수 목록에 입력된 논리값과 숫자의 텍스트 표현도 계산에 포함됩니다. 인수가 배열 또는 참조인 경우 해당 배열이나 참조 내 숫자만 계산됩니다. 빈 셀, 오류 값, 논리값 또는 텍스트는 무시됩니다.
이 함수는 다음 식을 사용하여 분산을 계산합니다.
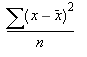
여기서 x는 표본 평균 AVERAGE(number1,number2,…)이고 n은 값의 개수입니다.
이 함수는 인수가 전체 모집단임을 가정합니다. 데이터가 모집단의 샘플인 경우에는 VAR.S 함수를 사용하여 분산을 계산하세요.
이 함수는 숫자뿐만 아니라 논리값이나 텍스트 값도 허용하는 VARPA 함수와 다릅니다.
데이터 유형
모든 인수에 숫자 데이터를 허용합니다. 숫자 데이터를 반환합니다.
예제
VAR.P(B3,C4,B2,D10,E5)
VAR.P(A1:A9)
VAR.P(R1C2,100,R2C5,102)
VAR.P(98,85,76,87,92,89,90) 는 결과 39.265306122448976을 반환합니다.